推荐系统学习
个性化推荐系统一般由四部分组成:信息采集模块、数据存储模块、推荐模块、推荐结果展示模块
1. 信息采集模块
- 用户信息:性别、年龄 …….
- 物品信息:种类、产地 … …
- 用户对物品的行为信息:显式行为、隐式行为

dir:列出当前目录下的文件以及文件夹
md: 创建目录
rd:删除目录
cd:进入指定目录
cd..:退回到上一级目录
cd\:退回到根目录
del:删除文件
exit:退出dos命令行
从经典的语言模型开始
ELMO — Embedding form Language Model
“Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence
to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. ”
首先用一个多层的 LSTM 将输入的序列编码为一个固定维度的向量(将输入进行翻转,以引入更多的 short dependencies)
然后用一个 LSTM 进行解码为输出序列
简单来说,Attention 可以理解为表示重要性的权重向量
为了预测或推断一个元素,使用注意力权重来估计其它元素与其相关的强度,并由注意力权重加权的值的总和作为计算最终目标的特征。
对Encoder层状态的加权
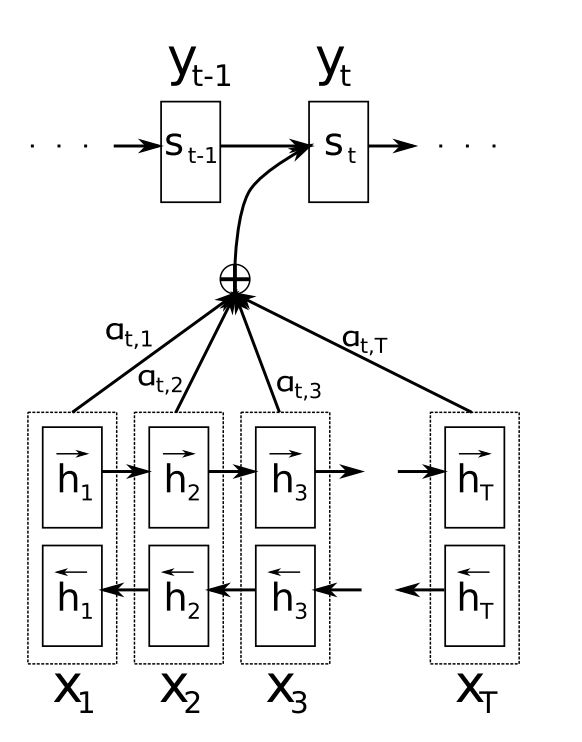
对于一个输入序列,我们需要将其转化为一个新的输出序列,其中输入、输出序列的长度可以是任意的长度
使用 Encoder-Decoder 框架
Sutskever et al., Sequence to sequence learning with neural networks. 2014
Bahdanau et al., (2014). Neural machine translation by jointly learning to align and translate
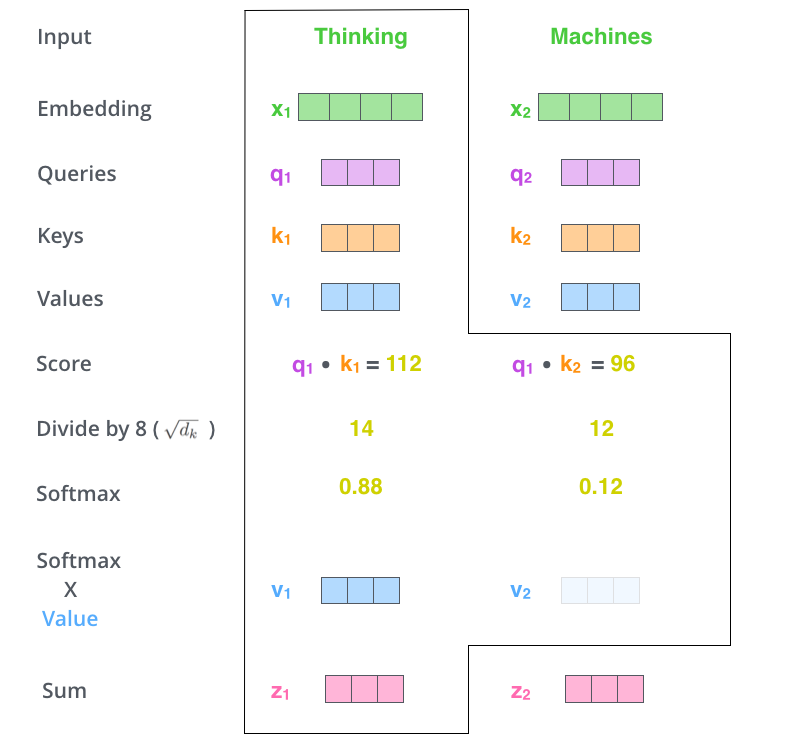
一个序列之间自己做 attention ,每一个词的 embedding 产生一个q vector,k vector,v vector, 用 q 去匹配每一个 k(计算dot-product),通过一个 softmax 映射为权重,再与 v 相乘,求和(这一步可以看做加权求和,就是 attention 的思想),得到最终的表示 z 。
生成多组 (Q,K,V)分别进行 self-attention 计算,将最后得到的多个 z 进行拼接。好处是多个 head 可以捕获不同的特征
![]()
![]()
PS:
Transformer 重点是如何做self-attention,其中 Q, K, V的计算比较重要,解释这篇论文比较好的博客有:
The Illustrated Transformer
Transformer模型笔记
论文来自:
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true