
Connecting Users across Social Media Sites: A Behavioral-Modeling Approach
Zafarani R , Liu H . Connecting users across social media sites: a behavioral-modeling approach.[C]// Acm Sigkdd International Conference on Knowledge Discovery & Data Mining. ACM, 2013.
Summary
这篇文章真得是绝了,信息量少,通过各种角度各种层面构建特征的方式可谓无所不用其极。但也值得学习。
而且必须拿到很多个社交网站的用户名数据,先验用户名数据集才比较好。
2013年发表在KDD上的文章,由此可见计算机发展得迅速。
Research Objective
解决跨社交媒体的用户标识问题:
- 识别用户的独一无二的行为模式
- 利用这些行为模式构建特征
- 使用机器学习方法进行用户的识别
Problem Statement
使用最少的信息确定两个用户是否是同一个身份。
已知一个用户在一些社交网站上的 用户名 ,现有一个候选用户名 c ,判断c是否是该用户在该社交网站上的用户名。
Methods
MOBIUS:行为模式与特征构建
MOBIUS: MOdeling Behavior for Identifying Users across Sites
在一个社交网络上,尽量使自己的用户名和别人的不同。人类个体倾向于选择 “not long, not random, and have abundant redundancy”的用户名,这可以帮助我们挖掘其中的特征。
从用户选择不同社交网络用户名的行为模式中可以提取一下三类特征:
- (candidate)Username Features:从候选用户名中提取的特征,例如:用户名的长度
- Prior-Username Features:例如:先验用户名的个数
- Username <-> Prior-Username Features :先验用户名和候选用户名之间的关系,例如:相似性
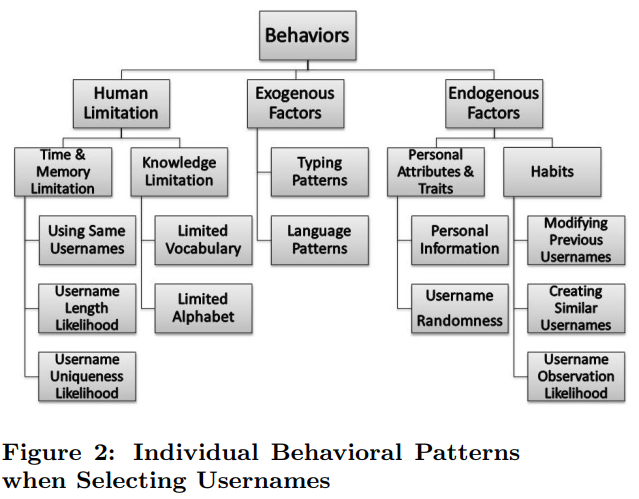
1. Patterns due to Human Limitations
Limitations in Time and Memory
选择之前用过的用户名 — > 将候选用户名 c 在以前的用户名中重复的次数作为一个特征
用户名的长度:$\min {u \in U} l{u} \leq l{c} \leq \max {u \in U} l_{u}$ 候选用户名的长度应该在之前用过的用户名的长度之间。 — > 将候选用户名的长度和以前用户名的长度分布作为特征。
用户名长度的分布特征可以用一个五元组来表示:
- 在之前的用户名中有多少个唯一的新的用户名 $uniqueness=\frac{|u n i q(U)|}{|U|}$
Knowledge Limitation
- 用户名中单词的数量
- 用户名单词数量的分布特征
- 用户名使用的字母的数量
2. 外在因素
- Typing Patterns
- Language Patterns :用户名的语言
3. 内部因素
- Personal Attributes and Personality Traits
- Personal Information:使用字母的分布情况
- Username Randomness:用户名字母分布的熵
- Habits
- Username Modification
- Generating Similar Usernames
- Username Observation Likelihood
Experiment
Naive Bayes
十折交叉验证
Feature Importance Analysis
odds-ratios(逻辑回归系数)
- 本文作者: Kelly Liu
- 本文链接: http://tiantianliu2018.github.io/2019/10/10/论文阅读《Connecting-Users-across-Social-Media-Sites-A-Behavioral-Modeling-Approach》/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!