
User Identity Linkage across Online Social Networks: A Review
Summary
Shu K , Wang S , Tang J , et al. User Identity Linkage across Online
Social Networks: A Review[J]. ACM SIGKDD Explorations Newsletter, 2017,
18(2):5-17.
这篇综述文章,总结了User Identity Linkage 问题的定义,现有的算法,数据集以及度量指标,并对该问题现存挑战和未来研究点进行了总结。
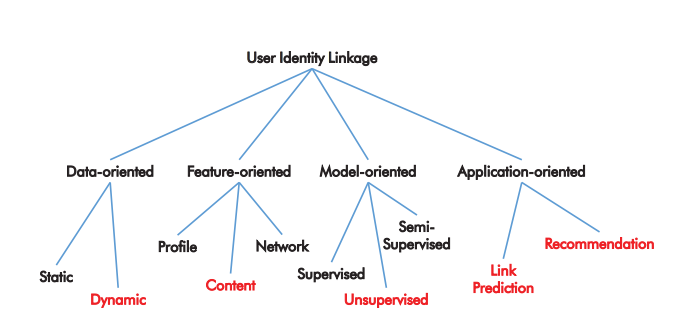
算法包括两个阶段:特征提取(Profile、Content、Network)、模型构建(监督、半监督、无监督)
数据集提供了两个可用的 public datasets:
- https://www.aminer.cn/cosnet
- http://www.mpi-sws.org/~ogoga/data.html
- http://www.ursino.unirc.it/pkdd-12.html
Research Objective
- 对 User Identity linkage problem 提出了一个正式的定义
- 提出了一个统一框架:特征提取、模型构建
- 数据集与评价指标总结
- 未来研究方向
Problem Statement
目前,越来越多的人使用多个社交平台,每个社交平台的功能不同,因此通过不同平台搜集的用户信息实际上是刻画每一个用户不同方面的特征。单一社交平台并不能捕捉用户的个性和兴趣。如果我们能够将不同平台上的同一个用户身份识别出来,利用用户来自多个不同社交平台的信息,就能够更好得理解用户的兴趣,为其提供更好的推荐和服务。另外,利用用户多个社交网络的信息,能够整合其社交模式,帮助解决冷启动和数据稀疏性问题。
Linking User Identity 定义:
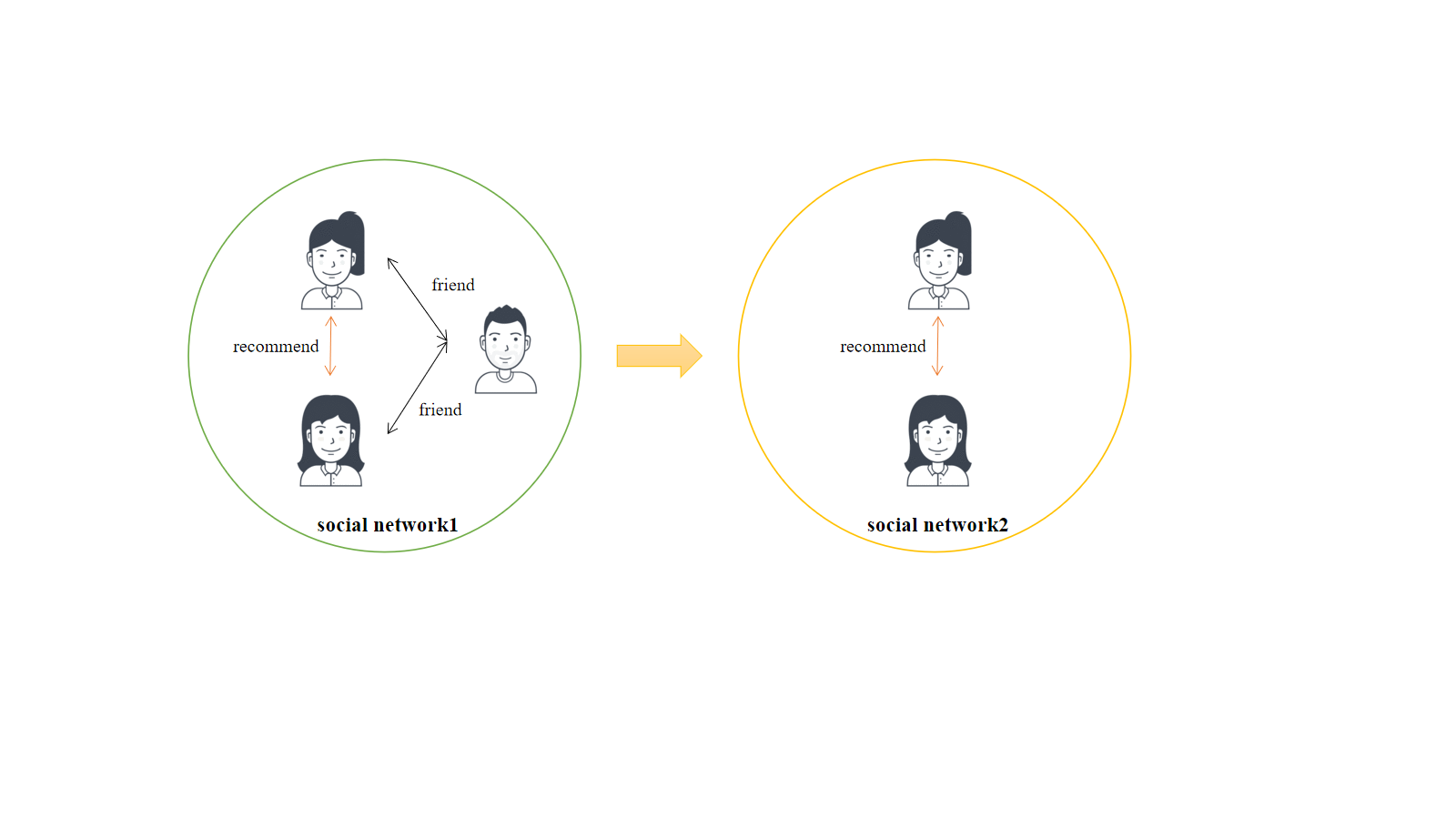
Enhancing Friend Recommendation
对于一个社交网络中的用户 A 和 B 有共同好友 C,因此会将用户 A 推荐给用户 B。若可以应用跨社交网络的补充信息,即使 A 和 B 在另一个社交网络中没有共同好友,将用户 A 推荐给 B 也是较好的 friend recommendation
Information diffusion
目前信息传播的研究是基于单个社交网络的。实际上,信息和流言得传播极有可能是跨社交平台的,研究什么样的信息更容易在一个社交内的网络内传播,什么样的信息更容易跨社交网络传播都是极有意义的。
Analyzing Network Dynamics
Identity Linkage Challenge
task:linking user‘s account on multiple social sites
- 用户社交网络上的身份信息可以与他在真实世界中的身份信息不相同
- 在线社交网络数据庞大,存在较多噪声数据、非结构化、不完整
在线社交网络中 user identity data 的特点:
- Profile inconsistency:不同的用户资料关注点,故意信息造假
- Content Heterogeneity:用户发布的内容反映了他的社会活动行为,在社交网络中产生的内容包括文字、图片、视频等,多源异构信息难以利用。数据孤岛。
- Network Diversity:某用户在不同社交平台的社交网路结构是不同的
Methods
Problem Definition
对于一个现实世界中的自然人P:
- Profile:对该用户的描述,eg:用户名、位置、年龄、职业等
- Context:表示用户活动的属性,包括时间、位置、文本、图片等
- Network:描述该用户与其他用户的社会关系

Framework
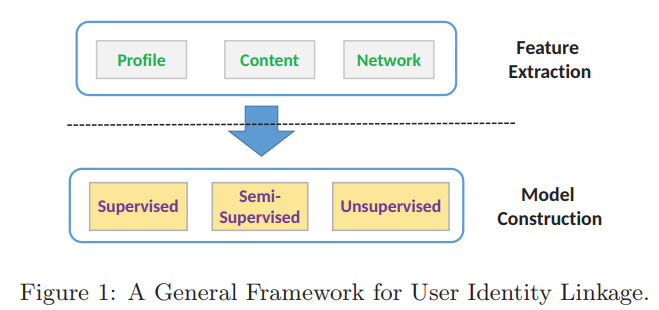
1. Feature Extraction
1.1. Profile Features
Public profile fileds
username
screen name:账户名
Biography:text description
Education
Avatar
根据用户资料识别用户身份的方法
- Distance-based
- 文本类型:Jaro-Winkler distance,Jaccard similarity, and Levenshtein (Edit) distance
- 图像:mean square error, peak signal-to-noise ratio, and Levenshtein distance
- Frequency-based
+ 文本类型:bag-of-word model, TF-IDF model + 其他:probabilistic model :Markov-chain model
1.2. Content Features
特征
- Temporal:用户活动的时间戳
- Spatial:有位置标签的,可以转成精确的经纬度;没有位置标签可以从用户发布的文字和图片中提取
- Post:文字或图像
方法
Interest-based:long-term topic modeling — 提取用户的核心兴趣
Liu et.al. Hydra: Large-scale social identity linkage via heterogeneous behavior modeling. In SIGMOD, 2014.
https://dl.acm.org/citation.cfm?id=2588559&preflayout=flat
Yuanping Nie, Yan Jia, Shudong Li, Xiang Zhu, Aiping Li, and Bin Zhou. Identifying users across social networks based on dynamic core interests. Neurocomputing, 2016.
Style-based:提取用户的写作风格。
- n-gram language model
- term-frequency analysis
Trajectory-based:具有时间戳的位置数据
1.3. Network Features
网络分类
- local network:只考虑直接相连的邻居(following/followee/friend relationship),是用户的ego-network
- global network:所有用户都要考虑进去
方法
- Neighborhood-based:邻居的数量,入度/出度,Dice coefficient ,common neighbors, Jaccard’s coefficient and Adamic/Adar score
- Embedding-based:
- first-order proximity
- second-order proximity
local network中,只有 Neighborhood-based 方法可以用,而 global network 上述两种方法都可以使用
1.4. Discussion
Profile features 最容易获得,但是也信息也是最容易被伪造的。由于不同社交平台会要求填写不同的用户资料,数据不一致性会更强。
Content features 会非常稀疏,因为用户可能并不活跃
Network features 噪声数据较多;一些特征必须是基于两个完全一致的网络提取的。
2. Model Construction
2.1 Supervised Model
典型的二分类问题
Aggregating methods
hybrid weighted form 混合加权的形式 combine 不同的相似性分数
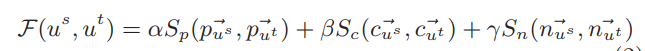
Probabilistic methods
预测类标签的概率分布
Maximum a posteriori (MAP) estimate 最大后验估计,可以通过贝叶斯理论求解
Boosting methods
通过多个弱假设学习一个强假设
Projection methods
学习一个映射函数:学习原始特征空间和在线社交网络中用户身份的潜在特征空间的映射关系
$\mathbb{D}$ 是衡量潜在特征空间中用户s和用户d之间距离的函数
2.2 Semi-Supervised Model
Propagation methods
seed matching user identity pairs
定义一个函数来计算用户身份的匹配程度,通过使用其已知的邻居信息以及其他特征
每一轮迭代过程中,匹配分数高的用户身份对被选择出来
两种propagation order:
+ Exhaust comparison :从未匹配对中找到,加入 + Local expansion 从现有匹配的用户对的邻居扩展候选匹配对扩充Embedding methods
在源网络和目标网络中,半监督嵌入方法通常共同学习用户身份的潜在特征。
2.3 Unsupervised Model
- Aligning Methods
- 对每一对候选 user identities 计算 affinity score
- 构建一个二分网络
- 根据得到的图G,形式化为一个优化问题,实现所有用户标识对的一对一匹配。
- Progressive methods
- 利用具有较强识别力的特征来寻找局部 ground truth
- 所有提取的特征都可以用来对剩余的未标记用户标识执行分类
2.4 Discussion
- 可扩展性
- 多样性
3. Summary of UIL Algorithms
Evaluation
1. Datasets
2. Evaluation Metrics
Prediction metrics
- TP:预测为 true,真实为 true
- TN:预测为 false,真实为 false
- FN:预测为 false,真实为 true
- FP:预测为 true,真实为 false
Identity-based Accuracy :
Ranking metrics
ROC 曲线
FPR(False Positive Rate)
TPR(True Positive Rate)
Area Under ROC curve (AUC)
Mean Reciprocal Rank (MRR)
- Mean Average Precision (MAP)
Related Areas
Open Issues and Future Research Directions
- Data Challenge
- Dynamic user identity linkage
- Jointly user identity linkage and recommendation
- Jointly user identity linkage and link prediction
- 本文作者: Kelly Liu
- 本文链接: http://tiantianliu2018.github.io/2019/09/23/论文阅读《User-Identity-Linkage-across-Online-Social-Networks:A-Review》/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!