
简单来说,Attention 可以理解为表示重要性的权重向量
为了预测或推断一个元素,使用注意力权重来估计其它元素与其相关的强度,并由注意力权重加权的值的总和作为计算最终目标的特征。
- step 1:计算其它元素与待预测元素的相关性权重
- step 2:根据相关性权重对其他元素进行加权求和
Attention 机制
对Encoder层状态的加权
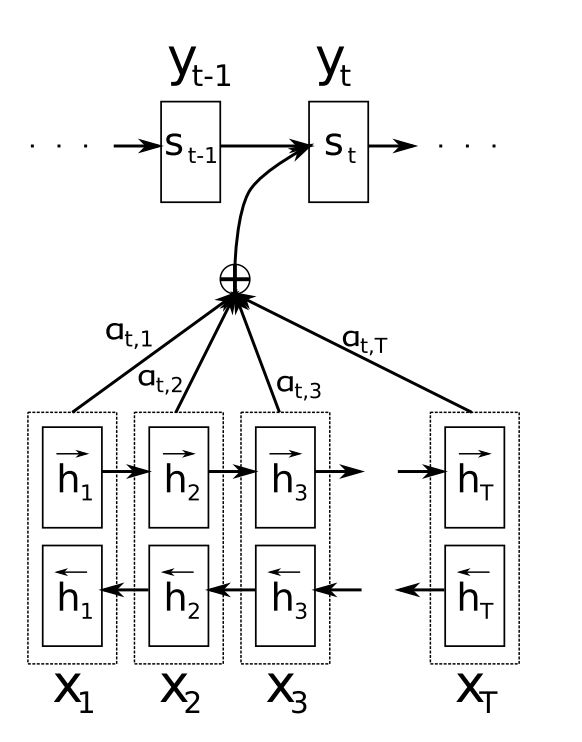
Seq2Seq
对于一个输入序列,我们需要将其转化为一个新的输出序列,其中输入、输出序列的长度可以是任意的长度
- 机器翻译
- 问答系统
- 语音识别
使用 Encoder-Decoder 框架
Sutskever et al., Sequence to sequence learning with neural networks. 2014
Bahdanau et al., (2014). Neural machine translation by jointly learning to align and translate
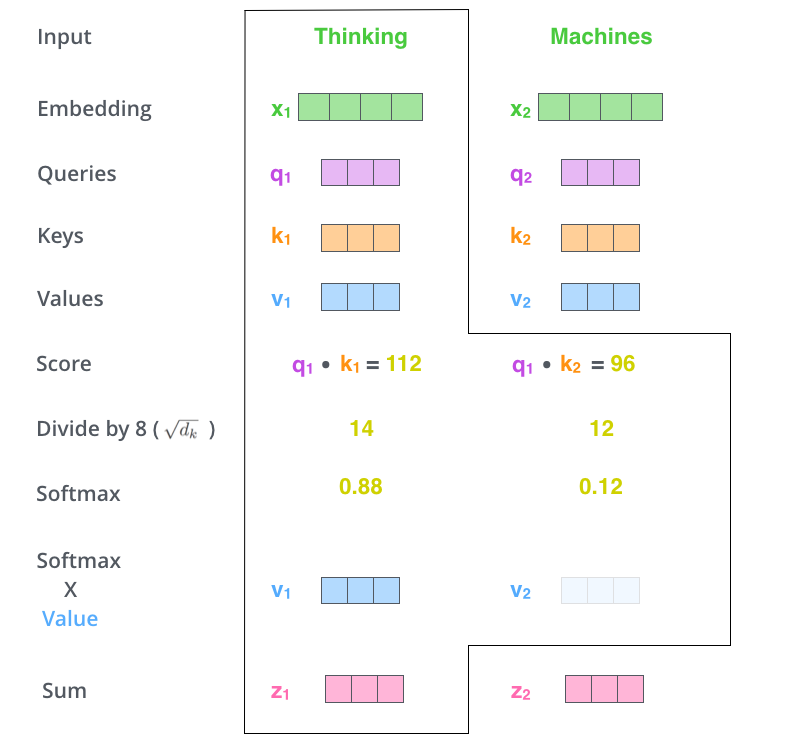
Self Attention
一个序列之间自己做 attention ,每一个词的 embedding 产生一个q vector,k vector,v vector, 用 q 去匹配每一个 k(计算dot-product),通过一个 softmax 映射为权重,再与 v 相乘,求和(这一步可以看做加权求和,就是 attention 的思想),得到最终的表示 z 。
Multi-head Attention
生成多组 (Q,K,V)分别进行 self-attention 计算,将最后得到的多个 z 进行拼接。好处是多个 head 可以捕获不同的特征
![]()
模型架构
![]()
PS:
Transformer 重点是如何做self-attention,其中 Q, K, V的计算比较重要,解释这篇论文比较好的博客有:
The Illustrated Transformer
Transformer模型笔记
论文来自:
- 本文作者: Kelly Liu
- 本文链接: http://tiantianliu2018.github.io/2019/08/17/Attention-is-All-you-Need/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!